在油田多年的勘探開發歷程中,積累的數據量從幾十MB增至上TB,并且仍然保持著幾何級數式的增長,油田在信息化實施過程中在不斷地改善存儲環境及方式,在當今國際油價持續下跌的嚴峻形勢下,如何發現數據隱藏的價值,提高數據利用率,真正做到用數據找油,指導油田生產,實現降本增效成為目前新疆油田亟待解決的問題.研究并利用大數據分析技術挖掘油田數據價值,實現開源節流創新創效,是當前國際油田發展的趨勢,也是國內油田的需要。
應用背景
截至2019年底,勝利油田油氣生產信息化建設基本實現全面覆蓋,實現35000余口油水井、540多座站庫的生產數據采集實時化和部分設備過程控制的自動化,建成生產現場視頻監控17000路,生產指揮中心125座。勝利油田工業控制系統中自動化采集控制設備有28萬臺(塊),數據傳輸設備有13萬臺(套),總計41萬臺。實現了工控前端參數的實時采集,改變了傳統人工采集模式,通過轉儲方式打通了工控網與辦公網之間的數據鏈路,采用針對性的數據建模方式實現了報警、預警的自動推送,推進了分析模式、評價方式、工作方法的改變,實現了對生產前端全過程數字化、可視化、遠程化管控,提升了對管理區的一體化聯動、精細化管理、精準化管控能力,推動了信息化與工業化融合,在降低建設投入、控制操作成本、提高勞動生產率、改善油藏經營效果等方面見到了明顯成效。
勝利油田目前工業控制體系已實現RTU在前端單井、設備層面的自控調節、人工控制調節等能力,而近年來隨著對數據及業務模型的深入挖掘及嘗試,像油水井聯合調整,多設備聯調聯方向的自動化控制條件也逐步成熟。
面臨的問題
生產信息化建設為勝利油田在企業管理和生產經營方面帶來了巨大效益,生產管理對生產信息化系統的依賴程度越來越高,而主要依賴的實時數據有著采集點眾多,綜合數據體量龐大,如何長期有效地保存數據、高效地使用數據,如何進行實時數據深化應用實現多設備聯調聯控,實時數據科研及仿真成為新時期急需解決的問題。
實時數據存儲及使用方面的需求。油田實時數據過多的存儲點,從前端RTU到SCADA,SCADA轉儲到關系庫,進行分析時再轉儲到分析庫,存儲經歷的點比較多,且實時數據使用關系庫作為主存儲,無法使數據長久在線,性能不能達到預定目標。油田實時數據傳輸時效性,過多的存儲點使得整個傳輸使用的鏈條較長,從而導致實時數據時效性變差,同時占用網絡資源多,繼而會出現報警延遲。
多設備聯控聯調方面的需求。多設備聯控聯調需要對調控目標進行多設備建模,雖然現在有一些模型實現了多參數建模,但眾多模型在不間斷運行過程中因數據供給能力不足、算法優化不到位表現出來的算力不足問題延緩了對計算要求較高的聯控聯調的實施,另外,數據采集、傳輸、分析、決策等過程完成之后的下行控制,控制參數數據也需要有相關的數據資源庫支持,來輔助決策后的自動控制。
實時數據科研方面的需求。從油田信息化建設向智能化建設邁進的過程中,越來越多的降本增效等專業方向上的科研及推廣帶動經濟效益提升,而目前的數據架構中提取久遠的數據非常困難,需要通過新型軟件設施來支持。因此,勝利油田生產實時數據的工業大腦研究及實踐,以提升實時數據的存儲能及計算能力,實時數據深化應用為目的,對工控網和辦公網數據架構、應用架構的演進,對實時數據使用流程進行梳理和優化,通過實施適合油田業務的邊緣計算中臺提升系統在數據存儲、檢索、計算方面的能力及效率,降低資源占用,低碳節能,提高系統的安全管控能力及可延展性,促進采集、存儲、應用、管理鏈條全方位提升,為油田智能化建設提供參考依據,并為邊緣計算、大數據分析、人工智能等領域提供基礎設施支持,具有長遠的戰略布局意義。
基于上述新的數據基礎設施實現易于定義的業務模型工具及高效的模型運算執行系統作為工業控制的數據決策及自動執行,從而實現生產運行數字孿生方案的落地,對進一步探索智能油田方向的應用實現有較大價值。
建設與應用
勝利油田按照制定的統一技術方案,通過優化數據架構,以新型實時數據庫為基礎實現邊緣計算中臺,利用可靠傳輸和大數據建模計算等技術,將油田陸上114個管理區,35000余口油水井,540個站庫的工控設備采集的數據由SCADA系統轉儲給邊緣計算中臺,實現41萬臺設備的在線數據管理,并可在邊緣計算中臺進行數據導航、分析展示、建模計算等功能,實現以數據為基礎,模型為主體,計算為導向,控制為目的的生產運行數字孿生系統。
勝利油田按照構建生態物聯網的理念,從初期對設備和系統進行了頂層設計,針對數據存儲及使用、聯調聯控、科研及仿真等方面的需求,統一規劃,研發了邊緣計算中臺,依托設備物聯技術、SCADA系統、PCS應用,綜合實現“云、邊、端”協同,提升邊緣分析應用的深度和優化效果,如圖1所示。
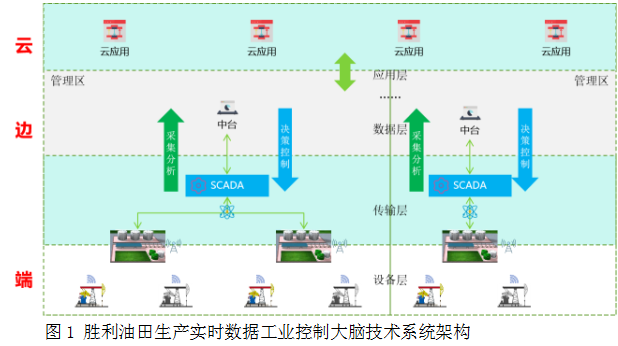
圖1 勝利油田生產實時數據工業控制大腦技術系統架構
應用多項技術
新型實時數據庫技術。專用實時數據索引,針對實時數據的高頻次、時間連續性(定長間隔)、采集點眾多等特性,實現專用的實施數據索引,相比使用關系型數據索引在處理實時數據時性能更好,支持的數據量更大。
分區分塊連續存儲,配合實時數據索引,通過按時間段分區,按指標分塊的方式,使同一指標數據按時間有序方式進行連續存儲,在范圍檢索時可以將連續的數據一次性取出,減少IO操作,從而性能在實時數據讀取上遠遠高于關系型數據庫。
邊緣計算中臺服務技術。通過建立邊緣計算中臺對實時數據庫中的數據進行數據治理、可視化展示、分析研究等,并以數據API即服務的形式提供出去,如圖2所示。
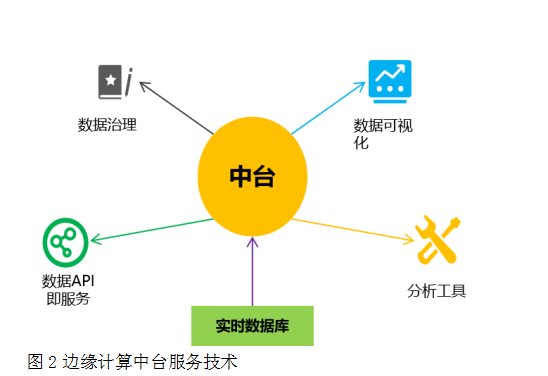
圖2邊緣計算中臺服務技術
實時數據在采集的過程中會面臨設備故障、網絡終端等很多情況導致的“假、啞、空”數據,這時從存儲源頭上進行數據治理及考核可以在最早的階段對數據進行治理清洗,如圖3所示。
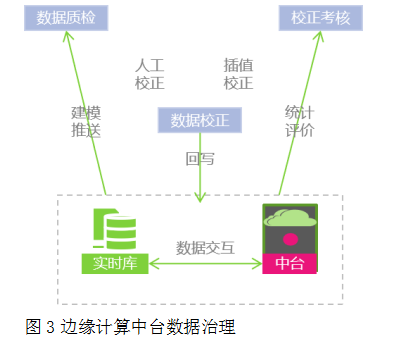
圖3邊緣計算中臺數據治理
業務模型計算技術。通過對目標設備及可影響目標設備的其它設備的參數集按閾值、趨勢等算法,依靠經驗公式形成權重控制,以目標分值評價為手段進行統一建模,進行實時的監控與診斷,分析可能出現的各種問題,進而可以在異常事件初期及時發現生產中的異常情況,以此來進行預警,提前采取預防措施,從而實現油田產量的穩產高產
[6]。利用區域級數據中臺倉庫的存力和算力對模型進行不間斷的剖析運算,生成報警、預警指導。如圖4。
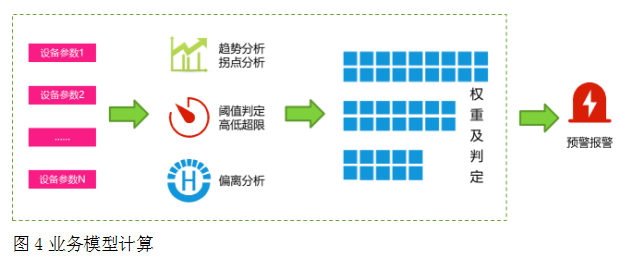
圖4業務模型計算
智能化報警處置技術。建立健全生產運行預警、報警處置參考數據庫,將預警報警結果分類為自動化執行、半自動化執行,人工執行等種類,按預警報警結果進行匹配,匹配成功的按照相關流程處理,如圖5。
自動化執行,匹配處置方式,自動下發指令;半自動化執行,形成處置參考轉人工核驗并執行;人工執行及無法匹配的直接分配到人。
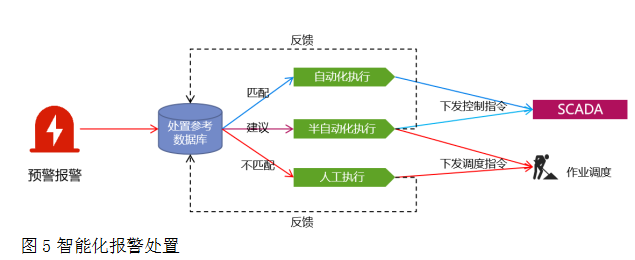
圖5智能化報警處置
工業大腦實踐應用。通過總體架構設計中的層次,按設備層生產數據-->傳輸層傳輸采集數據-->數據層存儲計算數據-->業務層應用數據-->下發控制指令-->傳輸到設備執行這一整個閉環實現自動偵測、采集、轉儲、應用、決策、調節的往復循環過程即實現了該業務方向的數字孿生,如圖6。
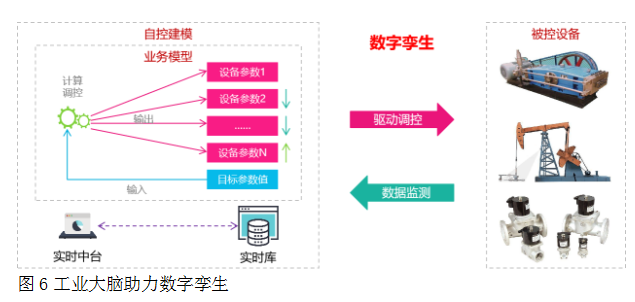
圖6工業大腦助力數字孿生
供排關系調整。通過實時數據中臺連續跟蹤油井實時工況,計算抽油機平衡度,根據設定的目標產能,調整電機供電頻率,自動控制沖次。在給定的抽油機平衡度范圍內限制電機供電頻率,保證一定的平衡度,降低供液不足風險,如圖7。
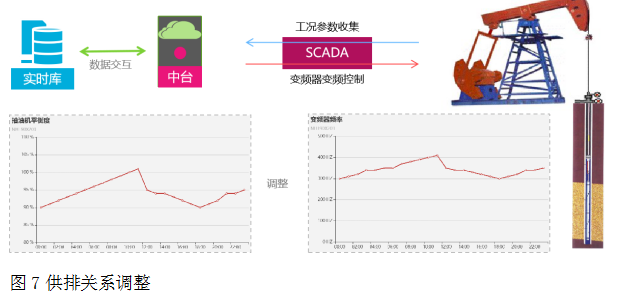
圖7供排關系調整
油井間開制度自動生成及執行。通過實時數據中臺連續跟蹤液面和功圖變化,分析計算關井時液面恢復時間和開井生產時間確定間開周期,根據已確定好的間開周期自動控制油井開井及停井,如圖8。
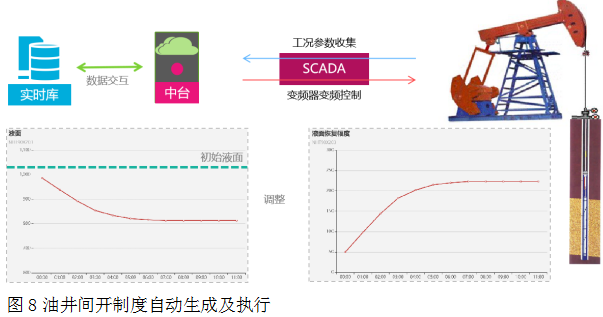
圖8油井間開制度自動生成及執行

 微信公眾號
微信公眾號
 微信視頻號
微信視頻號







 京公網安備11010502053156號
京公網安備11010502053156號